Enabling you to train the world’s most efficient AI models
ModelMill trains Logic-Based Networks. They're a wholly different architecture for AI that runs up to 54× faster while using 52× less energy than neural networks, on any CPU, MCU, or 32-bit semiconductor. No GPU. No cloud dependency. No new hardware.
Use Literal Labs’ AI model training platform to build, test & deploy logic-based, LBN AI models that run over 50x faster and use over 50x less energy than neural networks.







A better class of AI Built for the edge
ModelMill is the training platform for Logic-Based Networks — Literal Labs' proprietary AI architecture. LBNs aren't neural networks trimmed and compressed until they barely run. They're a ground-up rethink of how AI works, replacing floating-point multiplication with propositional logic. All while maintaining deep learning. The result is an AI model that’s smaller, faster, and more energy-efficient by design. Not by sacrifice.
Most platforms optimise then cripple models to survive at the edge. ModelMill trains models that thrive there.

Faster
MLPerf Tiny benchmark, ARM Cortex-M7. Logic instead of multiplication.

Less energy
Battery-powered deployments that run for years, not months.

No special hardware
Any 32-bit processor. ARM, RISC-V, x86, ESP, PowerPC. No new SoCs. No new capex.

Fully deterministic
Same data in, same answer out. Every time. No hallucinations. No variance.

Edge insights stall at the algorithm no longer
Edge devices are everywhere. They monitor sewers, make cars safe, monitor supply chains and manufacturing, and guard critical infrastructure. Deploying neural network AI on them? That’s where the industry has stalled. Until now.

Not a black box
ModelMill produces models whose training can be explained and whose decisions can be traced, understood, and audited. All with a clear chain of reasoning.
Embed on edge
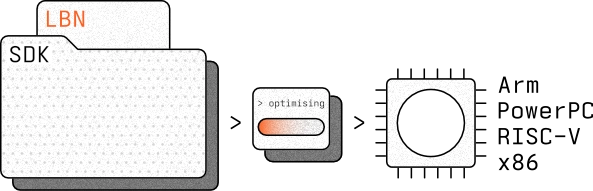
The LBN SDK ships as pure C. It runs on ARM, RISC-V, PowerPC, and x86 from any manufacturer, whether a sub-$1 MCU or a decades-old industrial processor. No new silicon. No board redesign.
What makes LBNs different?
LBNs aren't neural networks. They're a new class of AI model, built from logic instead of weights.
Learn more
54× faster
Inference speed benchmarked on ARM Cortex-M7 against a neural network FC Autoencoder, using the MLPerf Tiny anomaly detection specification.

52× less energy
455µJ per inference or forecast. Measured on a coin-cell equivalent battery. That's 10 years of predictions every 5 seconds with no new battery.
On-device, off cloud
LBNs run without a GPU or a cloud connexion. Inference happens on device, avoiding data streaming and round-trip latency. Typically under 5 kB, models fit where neural networks cannot.
The edge is 4 steps away
From raw data to a deployment-ready model, ModelMill handles the complexity so you don't have to. Import your data, set your target hardware, and let the platform train, benchmark, and package your LBN — ready to embed wherever you need it.
01 — Import
Your data,
processed & annotated
Upload your dataset via browser or API. CSV, JSON, or ZIP. Up to 5GB. Pre-processing, normalisation, and annotation are all handled in-platform.
02 — Target
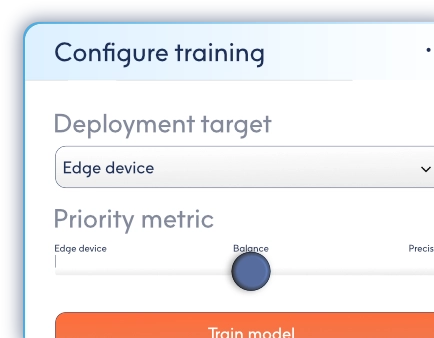
Tell it where
to run
Define your deployment hardware and set performance priorities — energy, speed, or memory. ModelMill configures itself around your constraints automatically.
03 — Train
ModelMill
does the work
ModelMill auto-configures and trains hundreds of LBN candidates in parallel, benchmarking each one against your target hardware and performance goals.

04 — Deploy
Your model,
small hardware
Select your candidate and ModelMill wraps it into a C SDK, complete with inference engine, build configuration, and documentation for embedded or server deployment.
Use cases and benchmarks
Looking to understand how and where LBNs can be deployed? From benchmarks to deployments, LBNs are working in production across automotive, utilities, supply chain, and semiconductors.


Helping hydro
Embedded hydro-informatics AI runs on battery sensors in sewers, monitoring harsh flows without cloud.
Learn more
Anomalous performance
Benchmarked 54× faster than like-for-like best-in-class for ToyADMOS anomaly detection.
Learn more
Predictive uptime
Predictive maintenance models reduced unplanned downtime by up to 50% and maintenance costs by up to 40%.
Learn more
Fast cars
Edge AI for cars: logic-based models deployed in tight spaces where only PowerPC can run.

Well stocked, well fed
Inventory forecasts cut from 4 hours to 3 minutes, with 2× WMAPE accuracy across thousands of SKUs.

Battery life
LBNs cut power use so far a coin-cell runs 10 years, up from 3 months on an RNN.


AIoT: 10-years on a coin cell
Embedded hydro-informatics LBN runs on battery-powered sensors for 10 years with a forecast generated every 5 seconds. The IoT sensor was first loaded with a Long Short-Term Memory (LSTM) neural network. But running inference every 5 seconds meant it couldn't be battery-powered. Instead, £15,000 of energy capex would be needed per sensor. ModelMill trained an LBN to be equally as accurate as the LSTM.
ModelMill trained LBNs compatible with battery-powered IoT sensors. While neural networks could only offer mains-powered operation.
Embedded on the edge and forecasting every 5 seconds, the LBN only consumes the equivalent power of a coin-cell battery in over 10 years of operation.
| Spec | Detail | Output |
|---|---|---|
| Power | Battery-powered | Continuous duty |
| Energy | 50 µJ per inference | Edge processing |
| Battery | Coin-cell equivalent | 10 year lifespan |
| Cycle rate | Every 5 seconds | Real-time forecast |
54× faster anomaly detection
LBNs benchmarked against the ToyADMOS dataset for anomaly detection on the MLPerf Tiny benchmark. The LBN achieved the same F1 score as the best-in-class neural network while running 54× faster on an ARM Cortex-M7 — the same hardware used in billions of devices worldwide.
54× faster inference than the best-in-class neural network on the MLPerf Tiny anomaly detection benchmark.
LBN accuracy is within ±2% of the neural network — without the computational overhead.
| Spec | LBN | Neural Network |
|---|---|---|
| Inference Speed | Fastest | Baseline |
| Energy per Inference | 455µJ | 23,660µJ |
| Model Size | <40kB | >500kB |
| F1 Score | Equivalent | Baseline |
LBN vs XGBoost
Logic-Based Networks versus gradient boosting: LBNs run up to 250× faster than XGBoost while using 130kB less memory. Same accuracy. Fraction of the resources.
Up to 250× faster inference than XGBoost on the same dataset and hardware.
130kB less memory required, making LBNs viable for embedded and edge deployment.
| Metric | LBN | XGBoost |
|---|---|---|
| Inference Speed | 250× faster | Baseline |
| Memory Usage | <40kB | >170kB |
| Accuracy | Equivalent | Baseline |
| Hardware Required | Any 32-bit CPU | Server-class CPU |

How it gives you more
GPUs and accelerators aren’t the future. They’re the bottleneck. Literal Labs forges fast, efficient, explainable, logic-based AI models from your data, enabling accurate, accelerator free AI performance everywhere from the battery-powered edge to cloud servers.
AI can’t scale if every model requires specialised hardware. We remove that barrier with logic-based networks. Faster, smaller, and explainable by design, they run efficiently on CPUs and microcontrollers, allowing you to avoid the GPU tax altogether.
Original, not just optimisation
LBNs aren’t an optimisation service. They’re high-speed, low-energy, explainable, logic-based AI models built from the ground up using Literal Labs’ exclusive architecture and algorithms. Most model training tools tweak what already exists. We craft what never did — an entirely new class of model, designed to perform where others can’t.
Learn more +


A billion to one
Literal Labs’ platform doesn’t stop at trial and error. It intelligently tests thousands of logic-based network configurations and performs billions of calculations to refine them. The result: one model, perfectly trained on your data, and for your deployment and performance needs. Precision forged at scale.
Learn more +AI without the GPUs
High performance shouldn’t demand racks of accelerators or spiralling cloud bills. LBNs run on microcontrollers, CPUs, and standard servers. They’re small enough for IoT, strong enough for enterprise. Already optimised, they require no GPUs, TPUs, or custom hardware. Deploy intelligence, not hardware bills.
Learn more +
Accuracy without excess
The average LBN model is less than 40kB, and without sacrificing accuracy. Benchmarking shows that they’re trained with only ±2% accuracy difference compared to larger, resource-hungry AI algorithms. Small in memory, LBNs are sharp in performance.
Learn more +GUI when you want, API when you don’t, seamlessly
You don’t need a large engineering team to get results. Literal Labs’ platform simplifies and accelerates training, benchmarking, and deployment in-browser or through API, so you can fit it seamlessly into the way you work best.
AI assisted configurations ![]()
A billion models to one. ModelMill performs billions of calculations and tests, and benchmarks thousands of models, all to help you find the single most accurate and performative model for your chosen deployment. And it does it automatically and intelligently, making the decisions that an AI engineer would, to guide your model speedily towards completion.
Benchmark without guesswork ![]()
Stop wasting time on trial-and-error benchmarking. ModelMill automates the process, comparing candidate configurations and models directly against your data and deployment constraints. The result: clear performance metrics without the endless grind. Automated benchmarking. No second-guessing.

From data to deploy, all in browser ![]()
Upload a dataset. Define your deployment target. Watch an LBN train. And then deploy it. ModelMill streamlines the process so that anyone can create efficient AI models in a browser tab or through their existing workflow via API. No complex installs. No GPU farm. Just data in, model out.
Simple model retraining ![]()
Today’s perfect model might need refinement tomorrow. ModelMill makes retraining simple: upload fresh data and it can automate improving your existing models. Browser or script, it adapts to your workflow. Continuous improvement, without the overhead.
Fine tune further ![]()
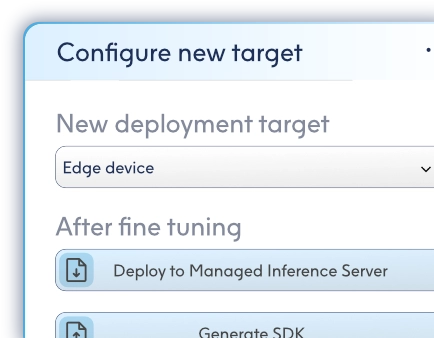
Once it has crafted your model, ModelMill can still refine it further. Adjust deployment parameters, push for lower energy, or tweak any accuracy trade-offs. ModelMill intelligently adapts, re-tuning the LBN to your exact requirements. Fine-tuning, without the fuss.
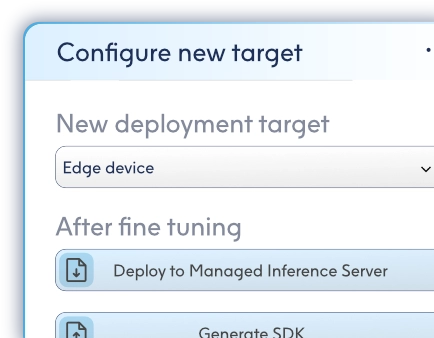
AI that performs where ever you need it
Deployment should be simple. On microcontrollers. On servers. On anything in between.
With Literal Labs, deployment is simple. LBNs are small enough for IoT devices, efficient enough for even battery-powered edge computing, and accurate enough for server workloads. One platform, countless deployment options.
Embed on edge
Small and silicon-agnostic. LBNs compile into a C SDK and embed on everything from coin-cell sensors to MCUs including Arm, RISC-V, PowerPC, x86, and architectures from other makers.


Execute on server
CPU-driven, compute-reduced, and cloud-ready. Deploy your custom LBN to a Managed Inference Server, stream data to it, and receive back predictions — no GPUs, no excess.

Be early to logic-based AI
Join early access to ModelMill used to train logic-based AI that runs faster, uses less energy, and fits the hardware you already have.
Book a 20 minute intro call & demo
Frequently asked questions
Join the companies already training LBN models that run faster, use less energy, and embed on the hardware they already own.
Get started with ModelMillFrequently asked questions
How do I train an AI model using Literal Labs? ![]()
Training LBN models with Literal Labs is designed to be straightforward. Upload your dataset to ModelMill via the browser-based interface, configure a small number of training options, and start training. ModelMill handles data preparation, model training, benchmarking, and optimisation automatically. Once complete, your trained model is ready for deployment to your chosen hardware.
What types of use cases does ModelMill support today? ![]()
It’s currently focussed on industrial and operational AI use cases, including anomaly detection, predictive maintenance, time-series forecasting, sensor analytics, and decision intelligence. These are problems where reliability, efficiency, and explainability matter as much as raw accuracy. Support continues to expand as new model types and capabilities are released.
Do I need AI or data science expertise to use ModelMill? ![]()
No. ModelMill is built to be usable by teams without dedicated AI or data science specialists. Most workflows can be completed through the guided web interface with minimal configuration. For engineering teams that want deeper control, the API provides advanced options and tighter integration, but this is entirely optional.
Do I need GPUs or specialised hardware to use it? ![]()
No. Model training is handled by Literal Labs' managed infrastructure, and trained models do not require GPUs or accelerators to run. Models produced by ModelMill are designed to operate efficiently on standard CPUs, microcontrollers, and edge devices, as well as on servers.
What infrastructure do I need to get started? ![]()
Very little. To begin, you only need a supported dataset and a web browser. There is no requirement to provision training infrastructure, manage clusters, or install complex toolchains. Deployment targets can range from embedded devices to cloud servers, depending on your use case.
How does Literal Labs differ from traditional ML platforms? ![]()
Traditional ML platforms are built around large, numerically intensive models that demand specialised hardware and complex operational pipelines. Literal Labs takes a different approach, producing compact, efficient models optimised for real-world deployment. The result is faster training, simpler deployment, lower energy consumption, and models that are easier to understand and maintain.
How do I get access, pricing, or start a pilot? ![]()
You can request access or discuss pricing directly by contacting us. The team offers guided pilots for companies that want to evaluate ModelMill on real data and real deployment targets. This allows you to assess performance, integration effort, and business value before committing further.