Edge AI. Right where it needs to be.
Most AI moves data from the edge to intelligence in the cloud. Edge AI puts the intelligence where the data is: on the chip, in the field, at the moment a decision is needed. The question is not whether the edge is viable. It's whichAI algorithm can make edge AI real. ModelMill trains LBNs: Literal Labs' deep-learning AI models trained for edge hardware. Small enough to fit. Fast enough to make decisions that matter.
Scalable edge AI for any embedded application
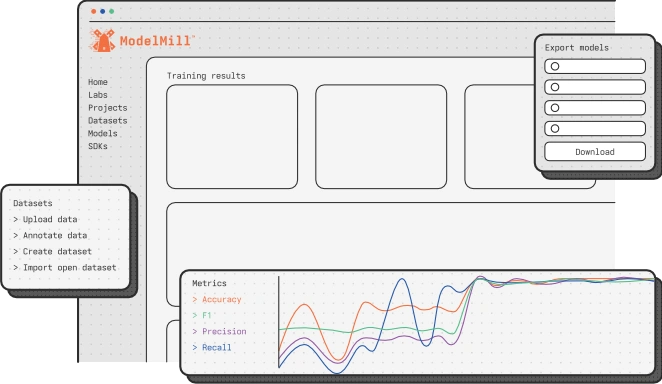
From the microcontroller inside a hearing aid to the processor managing an industrial robot, edge devices span an enormous range of hardware. What they share is what they require: intelligence that fits the chip, respects the power budget, and delivers decisions in real time. ModelMill trains LBNs for all of them.
Predictive maintenance
Bearing faults, pump cavitation, motor degradation — detected on the asset itself, before failure.
Automotive
In-cabin sensing, ADAS feature extraction, and predictive health monitoring — running directly on the ECU.
Drones
Autonomous classification and anomaly detection in air-gapped, battery-constrained platforms.
Robotics
Real-time fault detection and state classification on the robot's own embedded controller.

Industrial automation
Vibration, current, and acoustic monitoring running on the PLC or sensor MCU — no cloud round-trip.
Internet of Things
Intelligence at the node, not the gateway — years of battery life with inference running continuously.
Wearables & medical
Body-worn sensing, edge AI hearing aids, and health monitoring where data must not leave the device.
Intelligence that fits the hardware you already have.
The edge is not a scaled-down data centre. It is a completely different set of constraints. The best edge AI is not a neural network compressed into reluctant submission. It is a model architecture designed from the ground up to thrive under constraint. Logic-Based Networks are that architecture.
Runs on MCUs and CPUs
From low-power microcontrollers to industrial processors. No floating-point unit required. No GPU. No NPU. No Nvidia Jetson. The model runs on the 32-bit chip already inside your device.
Battery or mains powered
Efficient enough for years on a single cell. Fast enough for real-time control. At 52× less energy per inference than neural network equivalents, battery life is measured in years, not hours.
Minimal memory footprint
Small models. Predictable performance. Deterministic behaviour. The MLPerf Tiny anomaly detection model is 7.29 KiB. It fits on every industrial MCU made.
Explainable and deterministic by design
Every decision can be inspected. No opaque inference paths. The logical rules driving each classification can be read and audited, making these models deployable in regulated, safety-critical, and certification-constrained applications.
No connectivity required
Inference runs entirely on-device. The data is processed where it is generated, the decision is made immediately, and nothing is transmitted. Running without a cloud dependency is not a feature. It is the point.
Tiny edge. Larger edge. One training platform.
Edge AI covers a wide spectrum of hardware. At one end: microcontrollers with kilobytes of SRAM, no operating system, and a power budget measured in microwatts. At the other: industrial single-board computers with gigabytes of RAM and multi-core processors. The constraint changes. The principle does not. Intelligence should run on the device, not be forced into the data centre.
ModelMill trains for both the tiny and the large edge. Its AutoML approach searches the model architecture space automatically, targeting the specific hardware profile you specify. The result is a model sized and optimised for your device. Not a generic export that dictates your BOM.
Tiny edge: microcontrollers
Arm Cortex-M0, Cortex-M4, ESP32, and similar. SRAM in the tens of kilobytes. No operating system. Always-on, battery-powered, embedded inside the asset. These are the devices where neural networks cannot run. Logic-Based Networks can.
Embedded systems
Raspberry Pi, industrial SBCs, and mid-range embedded Linux platforms. More capable, but still power- and footprint-constrained compared to cloud hardware. Well-suited to edge AI cameras, audio processing, and multi-sensor fusion tasks that need a richer runtime environment.
Edge servers and gateways
Higher-compute edge nodes aggregating data from multiple sensors. They handle more complex inference tasks, but the same principle holds: on-site processing, no upstream data transfer, real-time decisions. Even here, a smaller, faster model is a better model.
Neural networks scale up
LBNs scale down.
Neural networks were designed for data centres: GPU racks, memory in gigabytes, and power drawn from the grid. The techniques used to shrink them (quantisation, pruning, knowledge distillation) produce models that are smaller, but structurally the same. They still require floating-point arithmetic. They still do not fit on a Cortex-M0.
Logic-Based Networks
Built for constraint
Logic-Based Networks are not AI models trained then shrunk. They are a different class of algorithm altogether. Their efficiency is not an optimisation pass. It is the architecture. A model that would require a GPU-backed cloud API as a neural network runs on a $3 chip as an LBN.
faster inference
Arm Cortex-M4, MLPerf Tiny anomaly detection benchmark. LBN vs best neural network result on identical hardware.
less energy per inference
Same benchmark, same hardware. The operational lifetime difference on a battery-powered sensor is not incremental.
Where edge AI already lives.
Edge devices are already doing more than most people realise. Hearing aids that classify acoustic environments without touching a server. Sewer sensors that run for a decade on battery. Vehicle ECUs that predict faults without requiring a new SoC. The range of what edge AI can do is wider than expected, and what every example shares is the same discipline: the decision happens on the chip, at the moment it is needed, without a round-trip to anywhere.
Edge AI hearing aids
Hearing aids are among the most constrained edge AI devices in existence: a sub-milliwatt power budget, a millimetre-scale processor, and a hard real-time audio pipeline. LBNs run on exactly this class of hardware, classifying acoustic environments, suppressing noise, and adapting gain without a cloud API call or a battery that empties in hours.
Edge AI cameras
Vision-based edge AI requires fast, local classification of image or video data: in security systems, quality inspection lines, retail analytics, and traffic management. On-device processing means no video stream transmitted to a server, no latency waiting for a cloud response, and no inference cost compounding across thousands of devices.
Predictive maintenance
Bearing degradation, pump cavitation, and motor faults detected from vibration and acoustic signals, classified on the sensor MCU in real time. The model runs on the same chip that drives the sensor assembly. No gateway. No cloud pipeline. No unplanned downtime.
IoT and smart sensors
Battery-operated field sensors classifying environmental conditions, detecting anomalies, or monitoring infrastructure for years on a single cell. The intelligence lives at the node. Only classification results leave the device, not raw data streams.
Wearables
Motion classification, health monitoring, and gesture recognition on body-worn devices. Wearables sit at the intersection of size, power, and privacy constraints: data must be processed locally, the battery must last days, and the processor fits on a fingernail.
Embedded control systems
Real-time classification feeding actuation decisions in automotive, industrial, and robotics applications. Deterministic output is a prerequisite for control systems, not a nice-to-have. LBNs provide it by design: same input, same output, every time.
Train once. Deploy on any hardware.
ModelMill trains and optimises models for on-device deployment across hardware from any maker. Its AutoML approach searches for the best-performing model within the constraints of the target platform, balancing accuracy, inference speed, memory footprint, and energy consumption without requiring the developer to specify any trade-offs manually. You tell it the hardware. It finds the model.
No Nvidia Jetson required. No specialised AI chip required. ModelMill produces edge AI that runs on whatever is already in your product.
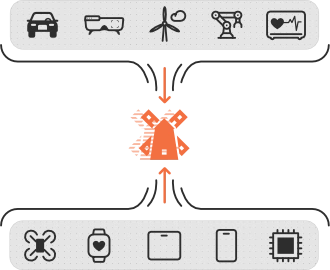
Microcontrollers (MCU)
Arm Cortex-M0, M3, M4, and M7 families. STM32, Nordic nRF, NXP Kinetis, and Renesas RA series. Any 32-bit MCU can run an LBN. No FPU, no SIMD extensions, no specialist silicon required.
Neural processing units (NPU)
Where an NPU is present, ModelMill can target it for additional throughput. But unlike neural network frameworks that require NPU hardware, LBNs run efficiently on the CPU alone. NPU availability is an optimisation, not a requirement.
Single-board computers
Raspberry Pi 4 and 5, BeagleBone, and industrial SBC platforms running embedded Linux. ModelMill generates portable C code with no framework dependencies. It runs without TensorFlow Lite, ONNX Runtime, or any ML library.
Edge AI chips and embedded systems
Purpose-built edge AI chips from Silicon Labs, Ambiq, Maxim Integrated, and others continue to multiply. ModelMill's output is hardware-agnostic C code. It deploys on any chip that can run a C compiler, including every edge AI chip on the market today and those not yet released.
What ModelMill delivers for every platform
A self-contained C SDK: the trained LBN, the inference engine, a build configuration for your target, and integration documentation. No runtime overhead. No ML framework dependency. No cloud connection at inference time. Drop it into your firmware and call two functions.
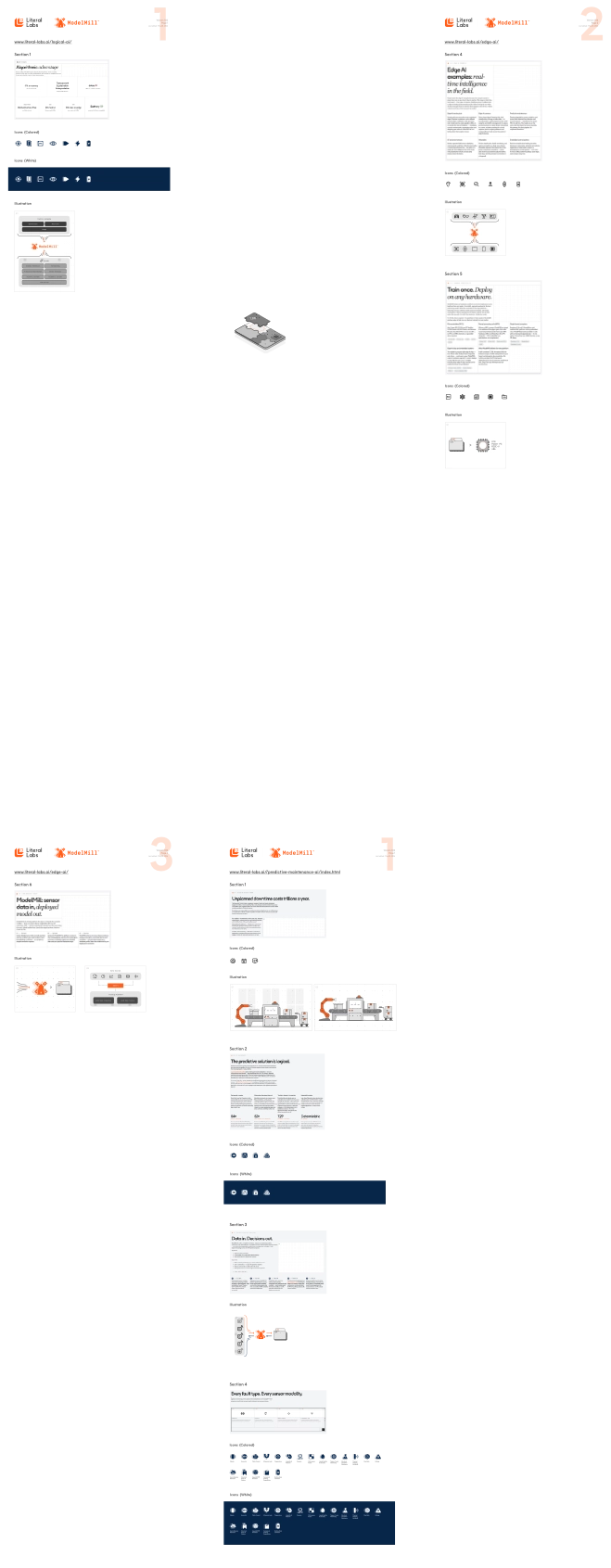
ModelMill: sensor data in, tiny model out.
ModelMill is the training platform for edge AI. It handles the complete workflow from raw sensor data to a deployable LBN in a self-contained C SDK, without requiring ML expertise from the team doing the work. Upload labelled data. Specify the target hardware. Receive a model that fits.

Gather labelled sensor data covering normal operation and the conditions you need to detect. Event-level labelling is sufficient. No sample-by-sample annotation required.
Upload to ModelMill. The platform constructs the training pipeline, searches the model space, and trains candidates against your labelled data and specified hardware target.
ModelMill surfaces accuracy, inference latency, energy consumption, and model size for each candidate, benchmarked against your hardware profile. Select the model that fits your deployment constraints.
Your selected LBN arrives as a self-contained C SDK: trained model, inference engine, build configuration, and integration documentation. No ML framework dependencies. No runtime overhead.
Integrate the SDK into your embedded firmware. The model runs on the target MCU alongside existing code. No cloud dependency. No ongoing inference cost. No network required at inference time.
Real-time inference on the hardware you already have. No retraining required as conditions change. The model classifies, detects, and decides at the speed the application demands. From here, the only question is what you build with it.
Train your first edge AI model.
ModelMill handles the full workflow end to end: labelled sensor data in, a complete AI model out.
Frequently asked questions
What is edge AI? ![]()
Edge AI is artificial intelligence inference that runs directly on an edge device — a microcontroller, embedded processor, industrial computer, or other local hardware — rather than on a remote cloud server. The data is processed where it is generated. The decision is made locally and immediately. No network connectivity is required at inference time, and no raw data needs to leave the device. Compared to cloud AI, edge AI offers lower latency, lower power consumption, better privacy, and no ongoing inference cost after deployment. The trade-off is that the model must fit within the hardware constraints of the edge device — which is precisely what ModelMill is built to solve.
What is the difference between edge AI and embedded AI? ![]()
The terms are often used interchangeably, and the distinction is more one of framing than architecture. Embedded AI typically refers to inference running on dedicated embedded hardware — microcontrollers, system-on-chip devices, and purpose-built embedded systems — usually in a fixed, single-purpose deployment. Edge AI is a broader term that includes embedded devices but also encompasses edge servers, gateways, and any compute hardware deployed outside a data centre. In practice, both require small, efficient models that run without cloud connectivity. Logic-Based Networks trained through ModelMill serve both use cases.
What is the difference between edge AI and cloud AI? ![]()
Cloud AI sends data from the device to a remote server for inference; the result is returned over the network. Edge AI runs inference locally, on the device. The practical differences are latency (microseconds to milliseconds for edge versus tens to hundreds of milliseconds for cloud), connectivity dependency (none required for edge versus always required for cloud), data privacy (data stays on device for edge versus transmitted for cloud), power consumption (milliwatts for edge inference versus kilowatts for cloud GPU inference), and ongoing cost (none after deployment for edge versus per-inference cloud fees). For applications requiring real-time decisions, intermittent connectivity, long battery life, or data sovereignty, edge AI is not a preference — it is a requirement.
Does edge AI require specialist hardware like an Nvidia Jetson? ![]()
Not with Logic-Based Networks. The Nvidia Jetson — and similar GPU-equipped edge compute modules — exist because neural networks require GPU-level compute even after compression. LBNs use bitwise operations on integers rather than floating-point matrix multiplication, so they run on any 32-bit processor. Cortex-M0, Cortex-M4, ESP32, STM32, Raspberry Pi, and custom SoCs all work without modification. ModelMill trains models targeted at your specific hardware — no AI-specific silicon, no specialist accelerator, and no Nvidia Jetson required.
Can edge AI models run on a microcontroller? ![]()
Yes. Logic-Based Networks run on any 32-bit microcontroller, including Arm Cortex-M0 devices with no floating-point unit. The inference engine is portable C code with no external dependencies. At the MLPerf Tiny benchmark, the LBN anomaly detection model occupies 7.29 KiB of flash — well within the constraints of standard industrial and consumer MCUs. A model that would require a GPU-backed cloud API using a neural network approach runs on a $3 chip using an LBN trained through ModelMill.
What are the best edge AI models for constrained hardware? ![]()
For MCUs, embedded systems, and other power- and memory-constrained hardware, Logic-Based Networks are the most efficient model class available. At the MLPerf Tiny benchmark — the standard measure for tiny edge AI inference — LBNs run 54× faster and consume 52× less energy than neural network equivalents on identical hardware, whilst achieving comparable accuracy. For classification, anomaly detection, and sensor intelligence tasks, no other approach comes close on constrained hardware. ModelMill trains LBNs targeted at your specific device, automatically optimising for the balance of accuracy and efficiency your application requires.
Can ModelMill be used to create an edge AI model zoo for a hardware platform? ![]()
Yes — and this is one of the more compelling applications for hardware makers. A model zoo is a curated library of pre-trained models, optimised and ready to deploy on a specific hardware platform. Rather than requiring each customer to train from scratch, hardware makers can use ModelMill to build a collection of application-specific LBNs — for anomaly detection, vibration analysis, audio classification, keyword spotting, and more — each benchmarked and validated against the target chip. Customers then select from the model zoo, integrate the SDK, and deploy without touching the training pipeline. If you are a silicon vendor, module maker, or embedded platform provider interested in building a model zoo for your hardware, contact us to discuss.